

 中文
中文Selection and Use of the Hadoop Yarn Scheduler
1. The introduction
Yarn has the role of resource management and task scheduling in the Hadoop ecosystem. A simple understanding of the architecture of the Yarn is given before discussing its constructors.
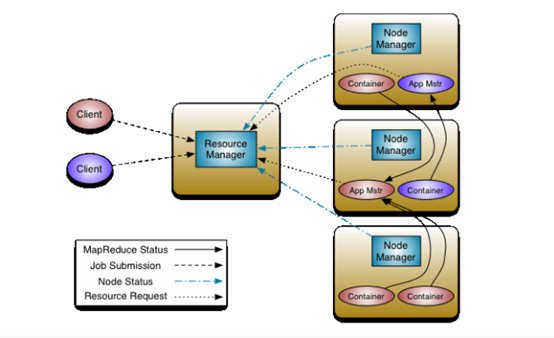
Above is the basic architecture of Yarn, where Resource Manager is the core component of the entire architecture, which is responsible for the management of resources including memory, CPU, and other resources throughout the cluster. Application Master is responsible for application scheduling throughout the life cycle; Node Manager is responsible for the supply and isolation of resources on this node; Container can be abstracted as a Container for running tasks. The scheduler discussed in this article is scheduled to be scheduled in Resource Manager, and then we’ll work on three schedulers, including the FIFO scheduler, the Capacity scheduler, and the Fair scheduler.
2. FIFO scheduler
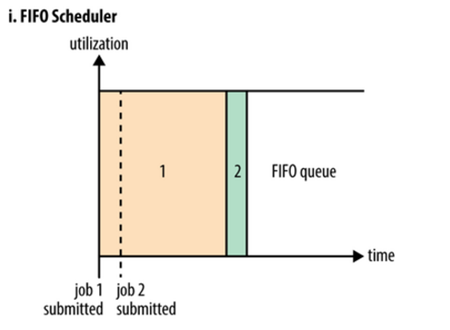
The diagram above shows the implementation of the FIFO scheduler. The FIFO scheduler is the First In First Out scheduler. A FIFO scheduler is one of the earliest deployment strategies used by Hadoop, and can simply be interpreted as a Java queue, which means that there can only be one job in the cluster at the same time. All applications are executed in the order of submission, and the Job after the completion of the previous Job will be executed in the order of the queue. FIFO scheduler to run in the form of cluster resources monopoly operation, this has the advantage of a Job can make full use of all resources of cluster, but for the running time is short, high importance or interactive query class MR jobs will be waiting for the row in front of the sequence of Job completion can be implemented, it would be caused if you have a very big Job running, so the back of the homework will be blocked. Therefore, although a single FIFO scheduling implementation is simple, there are many actual scenarios that cannot meet the requirements. This also triggers the emergence of the Capacity scheduler and the Fair scheduler.
3. Capacity scheduler
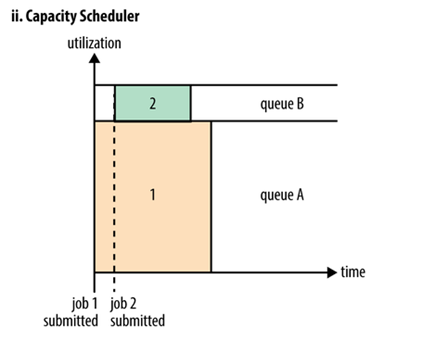
The diagram above is a schematic diagram of the implementation of the Capacity scheduler. The Capacity scheduler is also known as the container scheduler. It can be understood as a resource queue. resource queue is allocated by the user himself. For example, because the job requires dividing the entire cluster into two groups of AB and two, A queue can continue to divide, such as dividing A queue into 1 and 2 subqueues. Then the allocation of the queue can refer to the following tree structure:
—A[60%]
|—A.1[40%]
|—A.2[60%]
—B[40%]
The above tree structure can be understood as A queue occupying 60% of the entire resource, and the B queue takes up 40% of the total resources. There are two sub-queues in A queue, A. 1 takes up 40%, and A. 2 takes up 60%, which means that at this time, A. 1 and a.2 occupy 40% and 60% of the resources of A. Although has the concrete distribution of the resources of the cluster, but is not to say that A submission can only use it after the task was assigned to the 60% of the resources, and resources of the B 40% of the queue is in idle. As long as the resources in the other queues are idle, the queues that have the task commit can use the resources allocated to the idle queue, and how much is used depends on the allocation. The configuration of the parameters will be mentioned in the later article.
The Capacity dispatch appliance has several characteristics:
(1)Hierarchical queue design, this hierarchical queue design ensures that subqueues can use all the resources set by the parent queue. It is easier to allocate and limit the use of resources by hierarchical management.
(2)Capacity ensures that the proportion of a resource is set on the queue so that each queue will not consume the entire cluster’s resources.
(3) Security, each queue with strict access control. Users can only submit tasks to their own queues, and cannot modify or access tasks for other queues.
(4) Elastic distribution, free resources can be allocated to any queue. When multiple queues are competing, they are balanced in proportion.
(5) Multi-tenant renting, with the capacity limitation of the queue, multiple users can share the same cluster, and colleagues ensure that each queue is assigned to its own capacity, and the utilization rate is improved.
(6) Operability, Yarn supports the dynamic modification of the allocation of capacity, permissions, etc., which can be modified directly at run time. Also provides an administrator interface to display the current queue status. Administrators can add a queue at runtime; But you can’t delete a queue. The administrator can also suspend a queue at run time so that the current queue will not receive other tasks during execution. If a queue is set to stopped, then the task cannot be submitted to him or the subqueue.
(7) Resource based scheduling to coordinate applications for different resource requirements, such as memory, CPU, disk, and so on.
Configuration of related parameters:
A. Capacity: resource capacity of the queue (percentage).When the system is very busy, you should ensure that the capacity of each queue is satisfied, and if each queue application is less, you can share the remaining resources with other queues. Note that the sum of all the queues should be less than 100.
B. Maximum – capacity: resource use limit (percentage) of the queue. Because of resource sharing, the amount of resources a queue can use may exceed its capacity, and the maximum amount of resources can be limited by that parameter.(this is also the largest percentage of resources that the aforementioned queue can take up)
C. User-limit – factor: the maximum amount of resources per user (percent).For example, if the value is 30, the amount of resources per user cannot exceed 30 per cent of the queue capacity at any time.
D. Maximum – applications: cluster or at the same time in a waiting in the queue and application number of the running condition limit, this is a strong limitation, once the application in the cluster number more than the limit, subsequent submitted application will be rejected, the default value is 10000.Can be accessed by all queue limit the number of parameters of the yarn. The scheduler. Capacity. The maximum – applications Settings (which can be regarded as the default value), and can be accessed by a single queue parameters of the yarn. The scheduler. Capacity. < queue - path >. Maximum – applications Settings for their own values.
E. Maximum – am-resource-percent: the maximum amount of resources used to run application Application Master in the cluster, which is typically used to limit the number of applications that are active. The parameter type is floating point, and the default is 0.1, indicating 10%.The upper limit of the Application Master resources of all queues can be set by the parameter yarn. The maximum – am-resource-percent setting (which can be considered as the default), while a single queue can be set to its own value by parameter yarn. Scheduler.
F. State: the state of the queue can be STOPPED or RUNNING, if a queue in a STOPPED state, users don’t applications can be submitted to the queue or its child in the queue, similarly, if the ROOT queue in a STOPPED state, users can not submit the application to the cluster, but the RUNNING application will still be able to run normally, so the queue can exit gracefully.
G. Acl_submit_applications: specify which Linux users/user groups can submit applications to a given queue. It is important to note that this property is inherited, that is, if a user can submit an application to a queue, it can submit an application to all its subqueues. When configuring this property, the user or user group is split between the user group and the user group, and the user and user groups are separated by Spaces, such as “user1, user2 group1, group2”.
H. Acl_administer_queue: specify an administrator for the queue, which can control all applications of the queue, such as killing any application, etc. Again, this property is inherited, and if a user can submit an application to a queue, it can submit an application to all its subqueues.
4. Fair scheduler
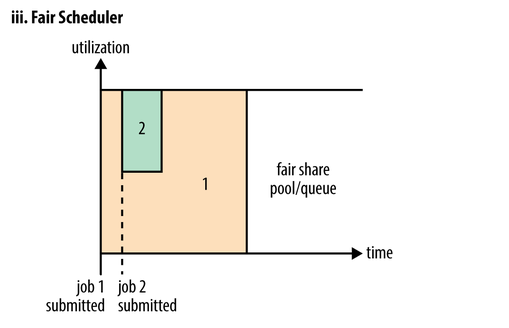
The above is a schematic diagram of the Fair scheduler’s execution in a queue. A Fair scheduler is a daily Fair scheduler. The Fair scheduler is a queue resource allocation method, which is the average resource for all jobs on the entire timeline. By default, the Fair scheduler simply does a Fair scheduling and allocation of memory resources. Only one task is running in the cluster, this task will take up the entire cluster of resources. When other tasks are submitted, those freed resources will be allocated to the new Job, so each task will eventually have access to almost as much resources.
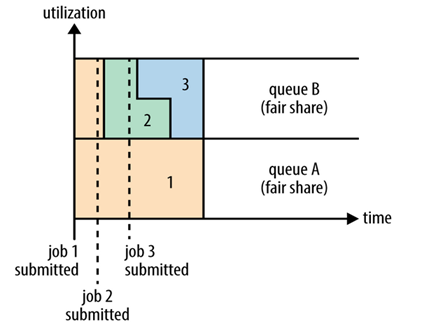
A fair scheduler can also work between multiple queues, as shown in the figure above, such as having two users A and B, each of which has A queue.When A starts A Job and B does not have A task to commit, A will get all the cluster resources;When B starts A Job, the task of A will continue to run, but queue A will slowly release some of its resources, and in A few minutes two tasks will get half of the cluster resources.Restart A second Job if the B and other task at run time, so it will be A and B in the queue first Job Shared queue B resources, also is the two Job queue B respectively using A quarter of the cluster resources, and the Job queue A half will still use cluster resources, as A result of the cluster resources eventually equal sharing between two users.
Configuration of related parameters:
(1) yarn. The scheduler. Fair. Allocation. File: the location of the “allocation” file, file allocation is used to describe a queue configuration files and their attributes.This file must be a strict XML file.If it is a relative path, you will find this file under your classpath (conf directory).The default value is “fair – scheduler. XML.”
(2) yarn. Scheduler. Fair.user-as-default-queue: whether the username that is associated with allocation is the default queue name, when the queue name is not specified.If set to false (and no queue name is specified) or no setting, all jobs will share the “default” queue.The default value is true.
(3) yarn. The scheduler. Fair. Preemption: whether to use “preemption” (priority, preemption), default to false, the functions in this version for test.
(4) yarn. The scheduler. Fair. Assignmultiple: is allowed in a heartbeat, in to send multiple container allocation information.The default value is false.
(5) yarn. The scheduler. Fair. Max. Assign: if assignmultuple to true, so in a heartbeat, up to send the allocation of the container number.The default is negative 1, unlimited.
(6) yarn. The scheduler. Fair. The locality. The threshold, the node: a float value between 0 ~ 1, said waiting for access to meet the node – the local conditions of containers, at most give up can not meet the needs of the node – local container number, give up the proportion of the size of the number of cluster nodes.The default value is -1.0, which indicates that no scheduling is abandoned.
(7) yarn. The scheduler. Fair. The locality. Threashod. Rack: ditto, meet the rack – local.
(8) yarn. The scheduler. Fair. Sizebaseweight: whether according to the size of the application (the number of Job) as weights.The default is false, and if true, the complex application will get more resources.
5.the summary
It is recommended to use a FIFO scheduler if the business logic is simple or when you are just exposed to Hadoop;Use the Capacity scheduler if you need to control some of the application priorities while also trying to make full use of the cluster resources.If you want multi-user or multi-queue equitable sharing of cluster resources, you use the Fair scheduler.I hope you can choose the appropriate scheduler according to your business requirements.