

 中文
中文Python USES Deep Neural Networks to Identify Siamese and British Short.
Let’s take a couple of pictures and see how the cat is Siam? Which cat is short?
First Siam

Second short

Have you ever been able to identify Siam and British short? Probably, it doesn’t seem to work. This is because there are too few materials, and we can see that these two pictures can be extracted from each other with too few short features. What if we Siam short put 100 picture, the short put 100 picture for your reference, and give a Siamese or English is just a photo can be identified is that a cat, if not recognized, also has a 90% can guess may be right. So if you provide 500 pictures of Siamese 500, are you more likely to guess right?
How do we identify Siamese and British short? It is first summarized the characteristics of the two cats such as facial color, eye color, etc., when have a picture to identify short, we will see if facial color, eye color can be characteristic of Siam.
Will computers be able to identify the two cats as well, after learning how to identify Siamese and English short?
So how do computers recognize images? Let’s look at how computers store images.
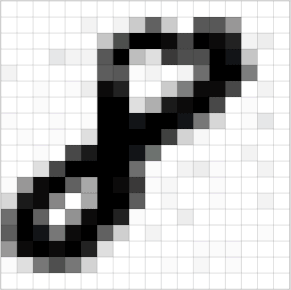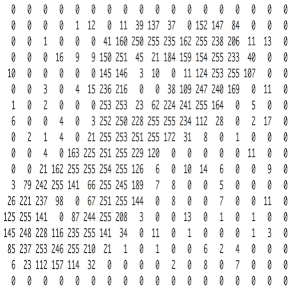
The image in the computer is a pile of Numbers in order, 1 to 255, which is a black and white picture, but the color varies from three primary colors – red, green and blue.
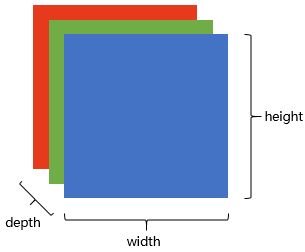
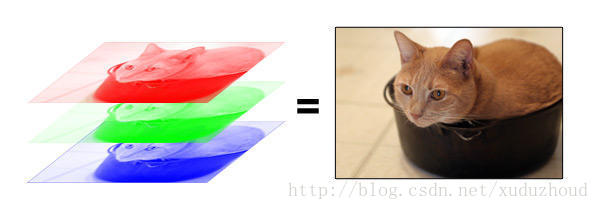
In this way, a picture is a cuboid in a computer! A cuboid with a depth of 3. Each layer is a number between 1 and 255.
To get a computer to recognize a picture, you have to let the computer know that it wants to recognize the features of the short image. Extracting features from images is the main task of identifying images.
Here is the main character, roll and neural network.(Convolutional Neural Network, CNN).
The simplest convolutional neural network looks like this.
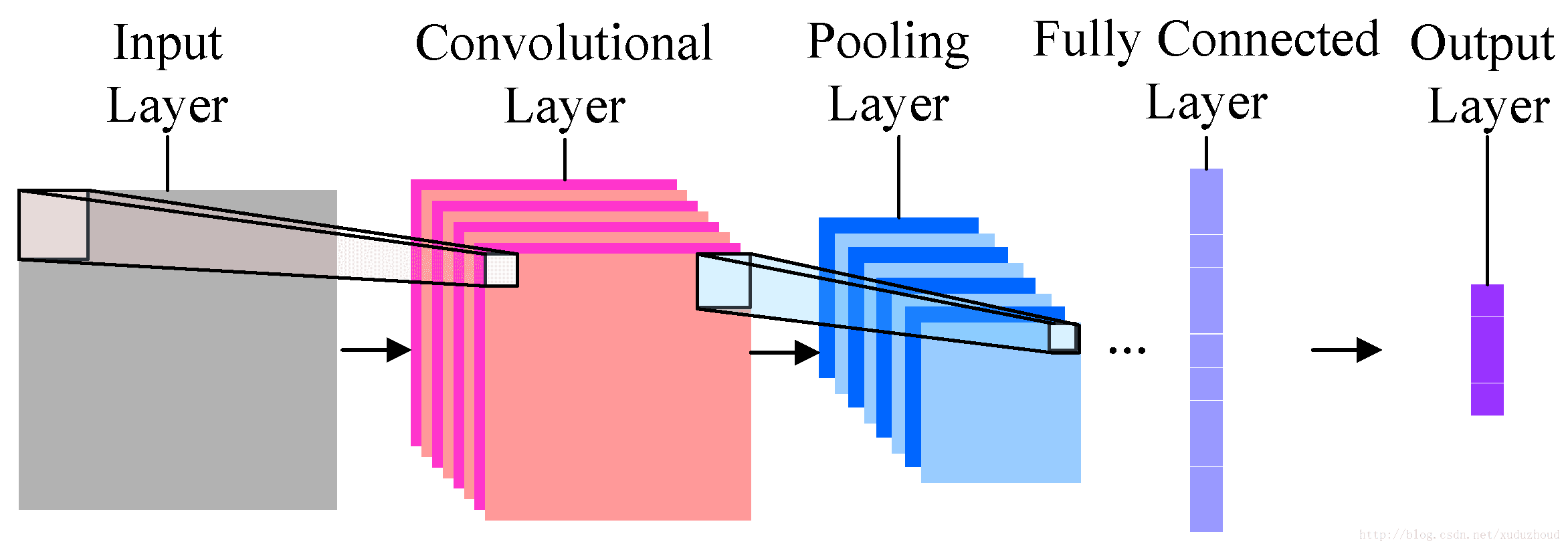
It is divided into input, convolution layer, pooling layer (sampling layer), full connection and output. Each layer compresses the most important identifying information and transmits it to the next layer.
Convolution layer: to help extract features, the deeper (multi-layer) convolutional neural network will extract more specific features, and the more shallow network extraction will be more obvious.
Pooling layer: reduces image resolution and reduces feature mapping.
Full connection: flattening the image feature, treating the image as an array, and using the pixel value as the characteristic of the value in the predicted image.
Convolution layer
The convolution layer extracts the features from the picture, and the image is stored in the computer according to the format we mentioned above (cuboid). First, extract the feature and how to extract it? Use the convolution kernel (weight). Do the following short operation:
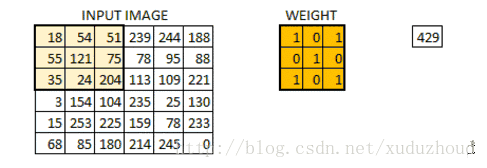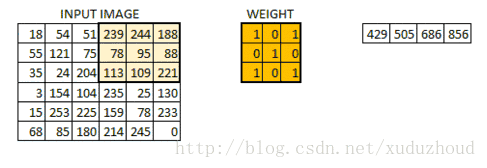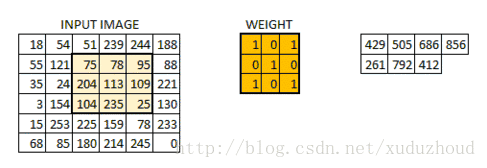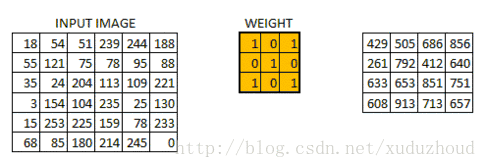
You look at the left and right matrices, and the matrix sizes are from 6×6 to 4×4, but the size distribution of the Numbers seems to be consistent. Look at the real picture:

The picture seems to be blurry, but what about the size of the two pictures? It’s in the following way: same padding.
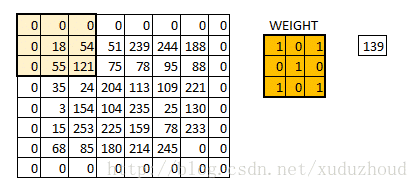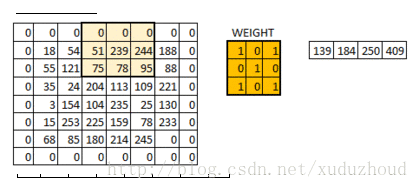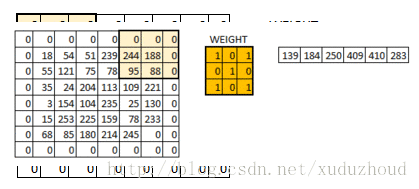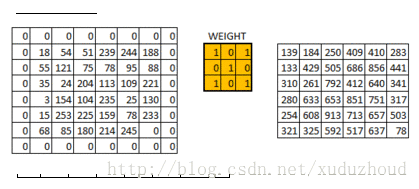
You add a circle of 0 around the matrix of 6×6, and then you have a 6×6 matrix, and why you add a circle of 0 is related to the size of the convolution kernel, the step length and the boundary. Do it yourself.
The above is a demonstration of using a 3X3 matrix on a 6×6 matrix. What does it look like to convolve in a real picture? The diagram below:

A 28x28x10 activation map (activation diagram is the output of the convolutional layer) is obtained by convolution of a 32x32x3 graph with 10 5x5x3 filters.
Pooling layer
Reduce image resolution and reduce feature mapping. How do you reduce it?
Pooling is done alone on each depth dimension, so the depth of the image remains the same. The most common form of the pooling layer is the maximum pooling.
You can see that the image is obviously getting smaller. As shown in figure:
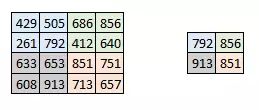
A new graph is obtained by extracting the maximum value of 2×2 on the two-dimensional matrix of each layer of the activation graph. The real effect is as follows:
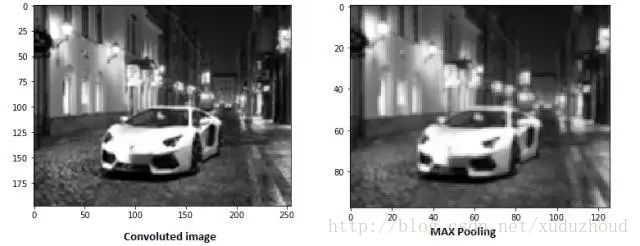
With the increase of convolution layer and pooling layer, the characteristics of corresponding filter detection are more complicated. As you accumulate, you can detect more and more complex features. There is also a problem of convolution kernel optimization, and multiple training to optimize the convolution kernel.
The following USES apple’s convoluted neural network framework, TuriCreate, to distinguish Siamese and English short. (first of all, I have been working late in win10 to reload the computer more than 3 times. The system should have WLS, and it is convenient to install turicreae under the enterprise version, MAC system and ubuntu system.)
First of all, prepare to train with 50 pictures of Siam, 50 long. The test USES 10 pictures.
Code :(development tool anaconda, python 2.7)
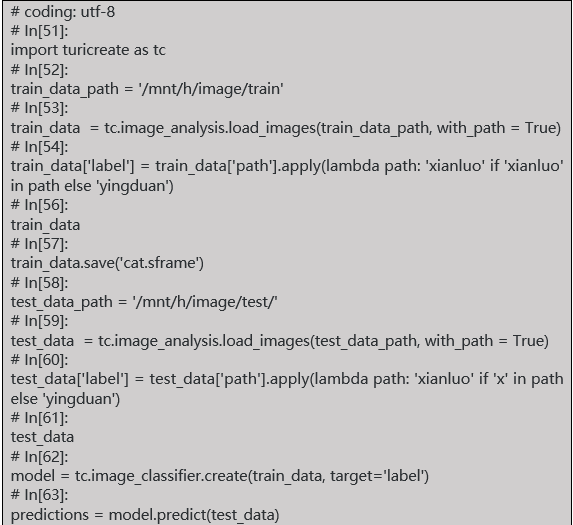

The data is placed in the image directory of the h disk, and I am installing ubuntu in win10, so the h disk is hung in MNT/down.
Test files :(x refers to Siam, y refers to short, so the name is to distinguish the cat type from the test pictures in the code)

test_data[‘label’] = test_data[‘path’].apply(lambda path: ‘xianluo’ if ‘x’ in path else ‘yingduan’)
The first results are as follows:
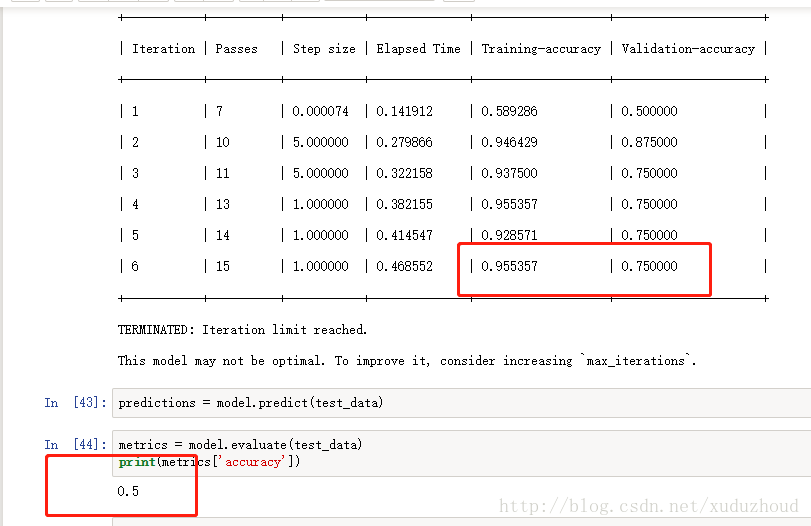
The accuracy of the training accuracy is 0.75 and the accuracy is 0.5. Well, it seems that the study is too little, and it will take three years to simulate the five years of the college entrance exam, which will increase the number of Siam and English short pictures to 100. I’m looking at the results.
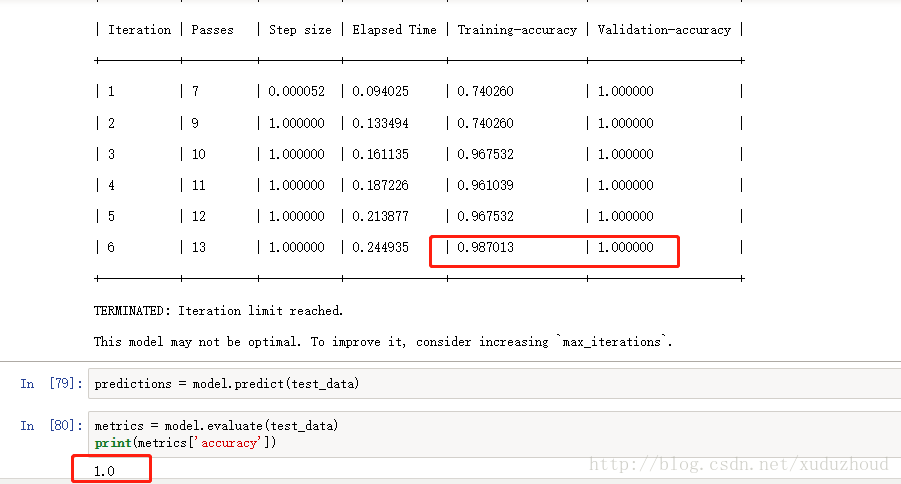
The accuracy of the training was 0.987, the accuracy of the test was 1.0, and the accuracy was 1.0.
See the results of turicreate recognition:
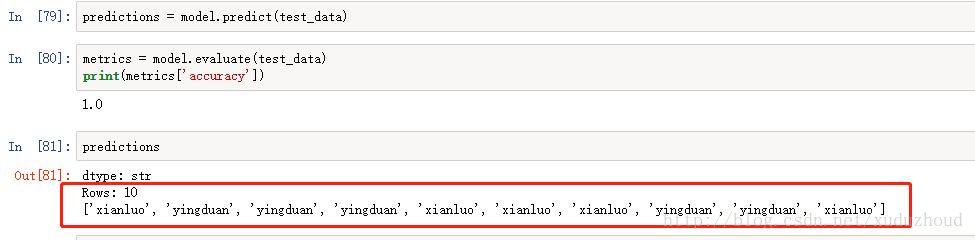
Our actual picture of the cat is :(red is the type of the real cat – in the code, according to the image name, green is the type of cat identified)
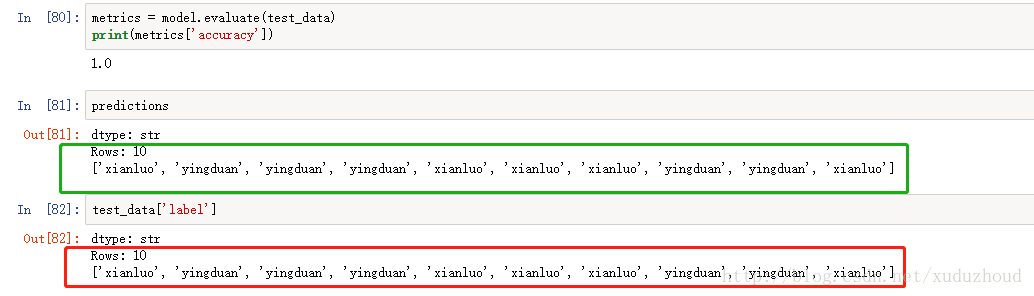
You can see that the two are consistent. The cow forces the training data only 200 pictures, can achieve this effect.